Technical description¶
This section describes the internals of a single WebLab-Deusto deployment. However, the architecture is enriched supporting federation. Go to the federation section for further information.
Architecture¶
Locally, WebLab-Deusto is based on the distributed architecture shown in following diagram:
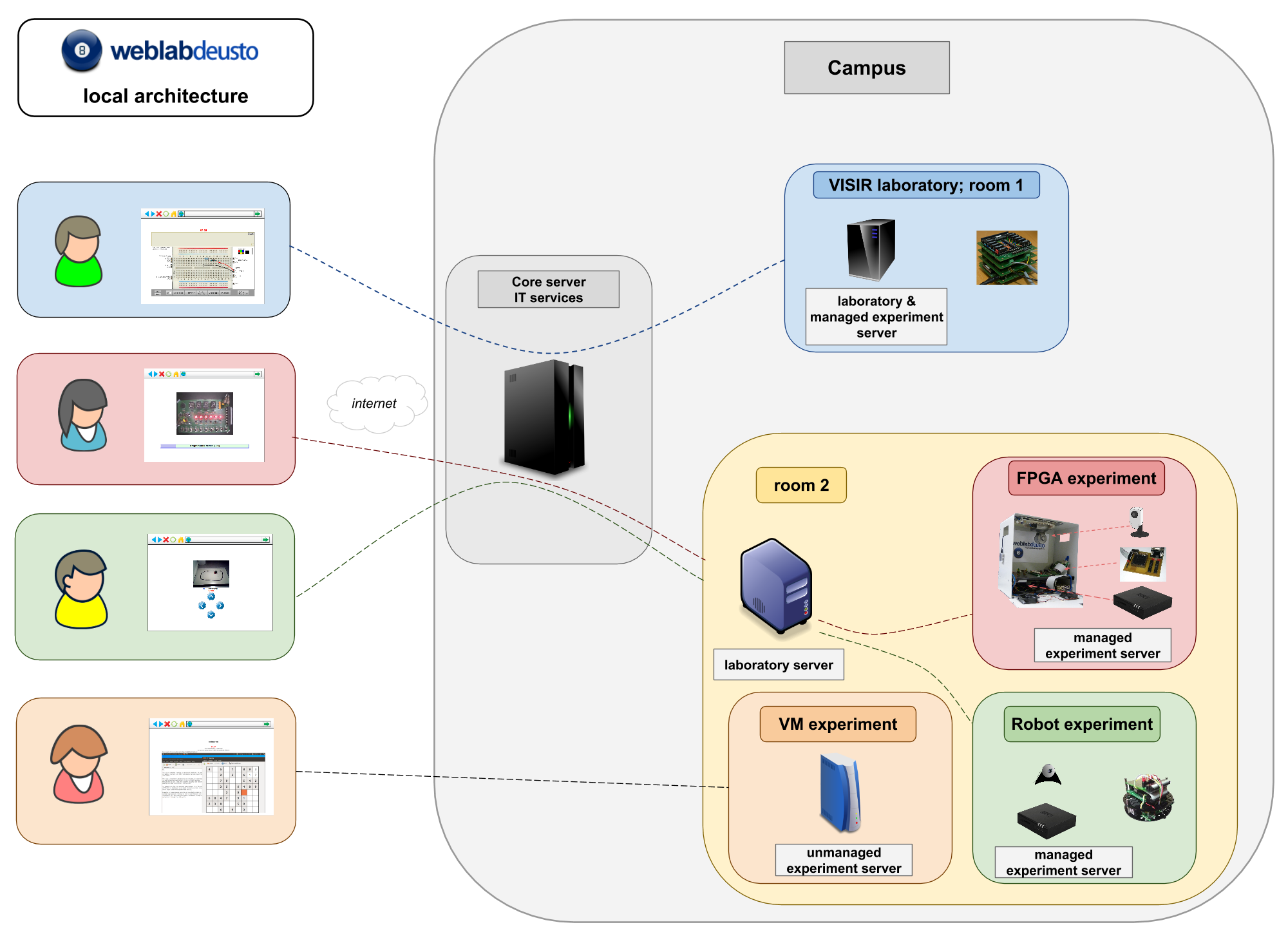
In this architecture, clients connect to the core servers, using commonly HTTP with JSON. These servers manage the authentication, authorization, user tracking, federation (sharing) and scheduling. From there, the system forwards requests to the laboratory servers, which forward them to the final experiments. One exception are the unmanaged laboratories (such as Remote Panels, Virtual Machines or so), where students directly connect to the final host directly (and therefore user tracking is lost).
As detailed later, the communications however enable that all these servers are spread in different machines in a network, or they can all be running on the same machine or even in the same process. For instance, the login server and the core server are usually always in the same process, while the laboratory server may be in other computer and the experiment server could be in the same process as the laboratory server. It just depends on the deployment desired and the required latency.
Technologies¶
WebLab-Deusto is developed in Python and using Open Source technologies (MySQL or SQLite, Redis, etc.), but we provide multiple APIs for developing laboratories in different languages. The user interface is developed in HTML, but it supports labs in other legacy technologies.
The server uses an ORM called SQLAlchemy. In theory, WebLab-Deusto should be independent of the database provider, but it has only been tested with MySQL and SQLite. For scheduling, WebLab-Deusto supports two types of back-ends: SQL database (again, MySQL and SQLite) and Redis, which is much faster.
Communications¶
WebLab-Deusto communications have been built on top of a pluggable system of protocols. When a component tries to connect to other server, it provides the WebLab-Deusto address of this server, and the communications broker will check what possible protocols can be used and it will automatically choose the fastest one (e.g., if both components are in the same process, it calls it directly instead of using any kind of serialization or communication).